
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- python list
- 이미지 생성
- 영어명언
- #일상영어
- #Android
- convexhull
- #1일1영어
- 영어
- #실생활영어
- findContours
- object detection
- #영어 명언
- #opencv
- word embedding
- tensorflow update
- 완전탐색
- tokenizing
- #프로젝트
- #영어
- 딥러닝
- #English
- c언어
- python 알고리즘
- opencv SURF
- TensorFlow
- keras
- #실생활 영어
- Convolution Neural Network
- text2img
- python __init__
- Today
- Total
목록02. Study (140)
When will you grow up?
알고리즘 문제를 풀 때 자주 사용되는 내장시퀀스데이터타입에 대해서 알아보자. python의 시퀀스(sequence) 데이터 타입은 다음과 같은 속성을 가진다. - 맴버십(membership)연산 : in 키워드 이용 - 크기(size) 메소드 : len(seq) - 슬라이싱(slicing) 속성 : seq[0:-1] - 반복성(iterability) : 반복문에 있는 데이터 순회 파이썬에는 문자열, 튜플, 리스트, 바이트 배열, 바이트 등 5개의 내장 시퀀스 타입이 있다. #list bin_list = [] print(type(bin_list)) # class 'list' #string bin_str = '' print(type(bin_str)) # class 'str' #tuple bin_tuple =..
새로운 언어를 배울때 일반적으로 'Hello World'를 출력으로 시작한다. 그 다음 숫자와 산술 연산을 이용하여 뭔가를 계산한다. 숫자는 정수(integer), 부동소수점(float), 복소수(complex)로 나타낸다. 사람에게는 10개의 손가락으로 표현하는 십진법(decimal)로 표현하는것이 자연스러운 반면에 컴퓨터는 상태의 신호(참, 거짓)를 주고받는 이진법(binary)로 표현하는것이 자연스럽다. 따라서 컴퓨터는 정보를 bit로 표현하고 8진법, 16진법 등 2의 배수 표현도 사용한다. 정수(integer) 파이썬에서는 정수를 int로 나타내며 불변(immuable)형이다. 불변형 객체는 변수와 객체 참조간 차이가 없고 컴퓨터 메모리에 의해 제한된다. -> (1024).bit_length()..
 Selenium을 이용한 네이버 로그인 접근 및 원하는 정보 얻기
Selenium을 이용한 네이버 로그인 접근 및 원하는 정보 얻기
크롤링(crawling)은 웹 페이지의 내용을 가지고 오는 것을 말하며 스크래핑(scraping)이라고도 부른다. 구굴, 네이버, 다음과 같은 검색 엔진 사이트들은 검색 속도를 높이기 위해 로봇(robot) 프로그램을 만들어서 자동으로 웹 페이지를 크롤링 할 수 있게 만들었으며, 무분별한 크롤링을 막고 제어하기 위해 로봇 배제 규약을 만들고 robot.txt 에 들어가서 크롤링 허가 / 불허가 여부를 이 파일에 적어 놓자고 약속한 규약이다. 구글에서서 로봇 정보를 보고 싶다면, https://www.google.com/robots.txt 접속 후 확인할 수 있다. ex) [Robots.txt] 예 ) 홈페이지 전체가 모든 검색엔진에 허용되지 않음 User agent: * Disallow: / 예 )홈페이..
정규표현식은 'regex' 표현하기도 하며, 특정한 규칙을 가진 문자열을 집합을 표현하는 데 사용하는 형식 언어이다. 그래서 python 뿐만 아니라 모든 언어에서 정규표현식을 지원하며, 언어별로 큰 틀은 비슷하지만 조금씩 사용방법이 달라 이참에 간단하게 python을 이용하여 정리하였다. 나는 기본적으로 데이터 크롤링과정이나 json포맷을 뭔가 전처리를 하고 싶을 때 이용하는 편이고, 특히 문자열을 다룰 때 정말 유용한 거 같다. meta string explain [string1, string2, ...] [] 안에 있는 문자들이 존재하는 지 검색 .{m, n} m회 이상 n회 이하를 표현할때 사용 () ()는 grouping 이며 추출할 패턴을 지정 . \n(Escape Character)를 제외한..
딥러닝 학습중 커널이 죽는 경우가 종종 발생하는데, 그럴때 항상 처음부터 모델을 학습하기에는 너무 오랜시간이 걸리고 다시 학습시 weight들의 초기값에 따라 결과가 조금씩 달라질 수 있는데, 이럴때 사용할 수 있는 방법이 epoch마다 weight 저장과 모델을 저장하는것이다. 또한, 매번 저장하면 용량이 커질수 있으니 val_loss가 낮아질때마다 저장시킬 수 있는 callback방법도 알아보자. 일반적으로 h5와 hdf5 형식으로 많이 저장하는데, 한번 특징을 알아보자 Hierachical Data Format Version 5(.h5, .hdf5) - 대용량 데이터를 저장을 위한 파일 포맷이며 NASA에서 대용량 데이터를 저장하기 위한 도구로 개발되었고 tree 구조를 가지고 있다. ref : h..
 워드 클라우드(word cloud)
워드 클라우드(word cloud)
워드 클라우드 (wordcloud) - 특정 데이터나 텍스트에 자주 등장하는 핵심단어 시각화 text : https://ko.wikipedia.org/wiki/%EC%9E%90%EC%97%B0%EC%96%B4_%EC%B2%98%EB%A6%AC wordcloud 모듈 설치 1 pip install wordcloud ex1 word cloud basic) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 import matplotlib.pyplot as plt %matplotlib inline from wordcloud import WordCloud, STOPWORDS t..
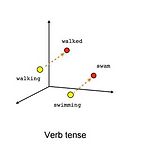 Gensim과 keras를 이용한 단어 임베딩
Gensim과 keras를 이용한 단어 임베딩
단어 임베딩(Word Embedding) - 단어 벡터 사이에 추상적이고 기하학적인 관계를 얻으려면 단어 사이에 있는 의미 관계를 반영해야되는데, 단어 임베딩은 언어를 기하학적 공간에 매핑하는 것이다. ex) 임베딩 공간에서는 동의어가 비슷한 단어 벡터로 임베딩. 즉, 멀리 떨어진 위치의 단어는 서로 의미가 다르며 거리 외에 공간의 특정 방향도 의미를 가질 수 있다. - 기하학적 변환은 ('king'벡터) + ('female'벡터) = ('queen'벡터) / ('서울') + ('중국') - ('한국') = ('베이징') 단어 임베딩 공간은 전형적으로 위와 같은 해석이 가능하고 잠재적으로 유용한 고차원 벡터를 특성으로 가진다. Word2Vec - 각 단어를 임베딩이라고 부르는 작고 밀집된 벡터(ex-10..
단어 사전(word index) : 숫자 매핑 사전 만들기. 즉, 단어별로 인덱스를 부여하는 것이다. keras에서 제공되는 preprocessing을 이용하면 간단하게 구현해볼 수 있다. 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 from keras import preprocessing samples = ['현재날씨는 10분 단위로 갱신되며, 날씨 아이콘은 강수가 있는 경우에만 제공됩니다.', '낙뢰 예보는 초단기예보에서만 제공됩니다.', '나 좋은 일이 생겼어', '아 오늘 진짜 짜증나' ] tokenizer = preprocessing.text.Tokenizer() tokenizer.fit_on_texts(samples) word_index = tokenizer.word_ind..
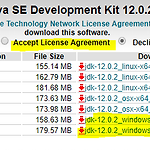 Natural Language Tokenizing (KoNLPy)
Natural Language Tokenizing (KoNLPy)
Korean tokenizing library : 파이썬 한국어 형태소 분석 라이브러리인 KoNLPy 가많이 사용되며, 설치하면 한나눔, 꼬꼬마, 트위터 등의 형태소 분석기를 쉽게 사용 가능. Window 10, Anaconda 환경을 기준 python 3.7을 사용한다. KoNLPy 설치 - 설치 전 java와 Jpype를 다운받고 설치해야한다. 1. Java 1.7 이상 설치 https://www.oracle.com/technetwork/java/javase/downloads/jdk12-downloads-5295953.html 에 접속 후 운영체제에 맞는 jdk 다운 및 설치 (window 10 이라 맨 아래의 것으로 다운 받았다) 2. 설치 후 JAVA_HOME Path 설정 내컴퓨터 오른쪽버튼 속..
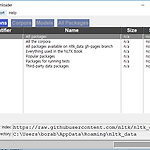 Natural Language Tokenizing (NLTK)
Natural Language Tokenizing (NLTK)
Natural Language Tokenizing - 텍스트에 대한 정보를 단위별로 나눈 것이 일반적이며, - 기본 단위로 자르는 것을 Tokenizing이라고 한다. English tokenizing library : NLTK, Spacy가 가장 많이 사용되며, 영어 텍스트에 대해 전처리 및 분석을 위한 도구로 유명 Window 10, Anaconda 환경을 기준 python 3.7을 사용한다. 설치 pip install nltk 1 2 import nltk nltk.download() http://colorscripter.com/info#e" target="_blank" style="text-decoration:none;color:white">cs all-corpora 텍스트 언어 분석을 위한 말뭉치..