
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
Tags
- 영어명언
- #실생활 영어
- #일상영어
- #영어 명언
- python 알고리즘
- findContours
- convexhull
- Convolution Neural Network
- 딥러닝
- opencv SURF
- python list
- object detection
- TensorFlow
- python __init__
- #1일1영어
- #프로젝트
- tokenizing
- c언어
- #opencv
- #실생활영어
- word embedding
- text2img
- 완전탐색
- #English
- 이미지 생성
- #Android
- keras
- #영어
- 영어
- tensorflow update
Archives
- Today
- Total
When will you grow up?
Natural Language Tokenizing (NLTK) 본문
Natural Language Tokenizing - 텍스트에 대한 정보를 단위별로 나눈 것이 일반적이며,
- 기본 단위로 자르는 것을 Tokenizing이라고 한다.
English tokenizing library : NLTK, Spacy가 가장 많이 사용되며, 영어 텍스트에 대해 전처리 및 분석을 위한 도구로 유명
Window 10, Anaconda 환경을 기준 python 3.7을 사용한다.
설치
pip install nltk
|
1
2
|
import nltk
nltk.download()
|
http://colorscripter.com/info#e" target="_blank" style="text-decoration:none;color:white">cs |

all-corpora 텍스트 언어 분석을 위한 말뭉치 데이터 셋이고 , book은 NLTK 언어 분석을 위한 예시 데이터셋이다.

nltk 설치가 끝났으면,
단어 단위 토크나이징 예제와 문장 단위 토크나이징을 확인해보자.
|
1
2
3
4
5
6
|
# 단어 단위 토크나이징
from nltk import word_tokenize
tokens = word_tokenize("I love korea, Korea. Nice to meet you")
print( tokens ) # tokenizing
print( nltk.pos_tag(tokens)) #pos_tag를 이용하여 다양한 함수 제공한다.
|
http://colorscripter.com/info#e" target="_blank" style="text-decoration:none;color:white">cs |
|
1
2
3
4
5
6
7
8
9
10
11
|
#문장 단위 토크나이징
from nltk import sent_tokenize
news = """Due to the mounting tension,
the leaders of Korea and Japan have not been able to hold a bilateral summit for some time.
But some expectations are that there would be an annually held trilateral summit between the leaders of South Korea,
Japan and China which could lead to a possible diplomatic breakthrough. """
print ( sent_tokenize(news))
http://colorscripter.com/info#e" target="_blank" style="color:#4f4f4ftext-decoration:none">Colored by Color Scripter
|
http://colorscripter.com/info#e" target="_blank" style="text-decoration:none;color:white">cs |
그 외에도 pos_tag를 이용하면 좋은 기능들이 많다.
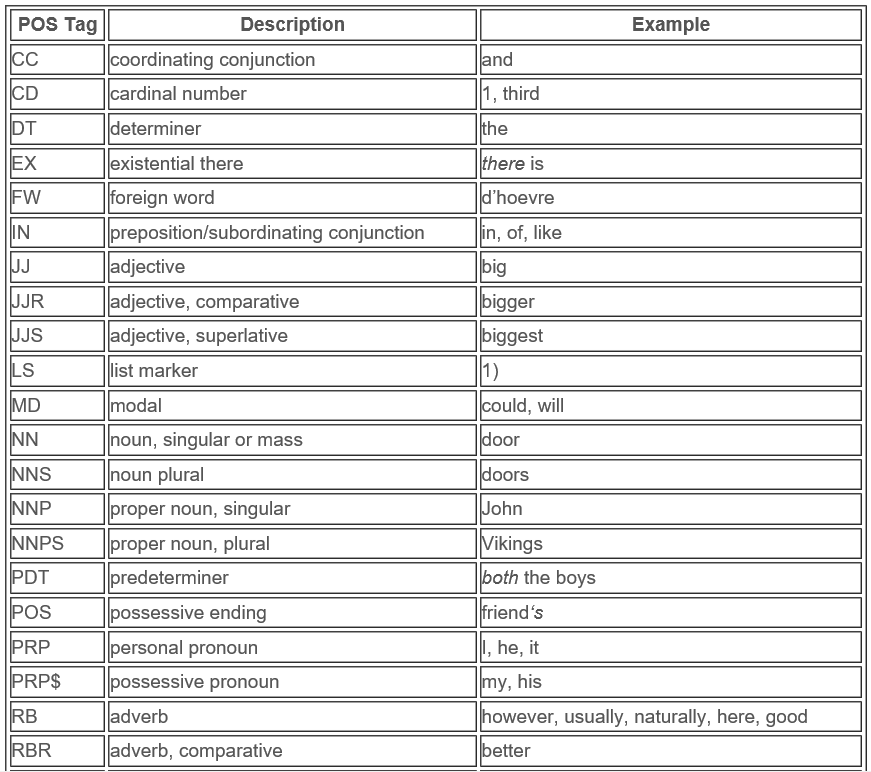
전체 소스 코드
'02. Study > Deep Learning' 카테고리의 다른 글
| 단어 사전, 특징 추출, 단어 표현 (0) | 2019.08.05 |
|---|---|
| Natural Language Tokenizing (KoNLPy) (0) | 2019.08.05 |
| 자연어 처리(natural language processing) (0) | 2019.08.05 |
| Transfer Learning (0) | 2017.11.28 |
| Natural Language Processing(using IMDB dataset) (0) | 2017.11.05 |
'02. Study/Deep Learning' Related Articles
more


Comments