
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- keras
- #영어 명언
- c언어
- #실생활영어
- python 알고리즘
- opencv SURF
- #Android
- #프로젝트
- python list
- 이미지 생성
- #1일1영어
- #English
- #실생활 영어
- convexhull
- object detection
- text2img
- tokenizing
- word embedding
- tensorflow update
- 영어명언
- #영어
- 영어
- 딥러닝
- findContours
- python __init__
- #opencv
- TensorFlow
- Convolution Neural Network
- #일상영어
- 완전탐색
- Today
- Total
When will you grow up?
 Natural Language Tokenizing (KoNLPy)
Natural Language Tokenizing (KoNLPy)
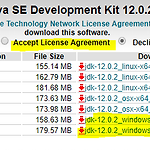
Korean tokenizing library : 파이썬 한국어 형태소 분석 라이브러리인 KoNLPy 가많이 사용되며, 설치하면 한나눔, 꼬꼬마, 트위터 등의 형태소 분석기를 쉽게 사용 가능. Window 10, Anaconda 환경을 기준 python 3.7을 사용한다. KoNLPy 설치 - 설치 전 java와 Jpype를 다운받고 설치해야한다. 1. Java 1.7 이상 설치 https://www.oracle.com/technetwork/java/javase/downloads/jdk12-downloads-5295953.html 에 접속 후 운영체제에 맞는 jdk 다운 및 설치 (window 10 이라 맨 아래의 것으로 다운 받았다) 2. 설치 후 JAVA_HOME Path 설정 내컴퓨터 오른쪽버튼 속..
 Natural Language Tokenizing (NLTK)
Natural Language Tokenizing (NLTK)
Natural Language Tokenizing - 텍스트에 대한 정보를 단위별로 나눈 것이 일반적이며, - 기본 단위로 자르는 것을 Tokenizing이라고 한다. English tokenizing library : NLTK, Spacy가 가장 많이 사용되며, 영어 텍스트에 대해 전처리 및 분석을 위한 도구로 유명 Window 10, Anaconda 환경을 기준 python 3.7을 사용한다. 설치 pip install nltk 1 2 import nltk nltk.download() http://colorscripter.com/info#e" target="_blank" style="text-decoration:none;color:white">cs all-corpora 텍스트 언어 분석을 위한 말뭉치..
자연어 처리(natural language processing) NLP라고 불리며, 컴퓨터가 자연어의 의미를 분석하여 처리할 수 있도록 하는 과정이다. 크게 자연어 전처리, 학습, 활용 분야로 나뉠수 있다. 자연어 전처리 (natural language preprocessing) - 자연어 tokenizing : 형태소 분석, 단어 or 문장으로 나누기 등 - 단어 Indexing : dictionary 만들기 등 - 단어 representation : One hot encoding, Word Embedding, Word2Vec 등 학습 (Training) - ANN (Artificial Neural Network) - DNN (Deep Neural Network) - RNN (Recurrent Neur..