
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- tensorflow update
- c언어
- #Android
- 영어
- TensorFlow
- #프로젝트
- #opencv
- 딥러닝
- #English
- tokenizing
- convexhull
- Convolution Neural Network
- object detection
- #실생활영어
- #영어
- python 알고리즘
- text2img
- 이미지 생성
- keras
- python list
- findContours
- #실생활 영어
- #일상영어
- #영어 명언
- 영어명언
- python __init__
- word embedding
- #1일1영어
- 완전탐색
- opencv SURF
- Today
- Total
When will you grow up?
[SOTA OCR] GOT OCR-2.0 본문
GOT-OCR2.0은 광학 문자 인식(OCR) 분야에 새로운 AI 모델입니다. 이 모델은 기존 OCR 시스템의 한계를 극복하고 문서 처리 능력을 크게 향상시켰습니다.
OCR-2.0의 특징
- 엔드투엔드 모델: 복잡한 파이프라인 대신 통합된 아키텍처
- 낮은 학습 및 추론 비용: 합리적인 파라미터 수로 효율성 확보
- 다양성: 일반 텍스트뿐만 아니라 수식, 악보, 차트 등 다양한 시각적 "문자" 인식 가능

일단, 그럼 한글 성능을 살펴보자
해당 내용은 나무위키 문서를 캡쳐했다.
입력

plain texts OCR mode 추론 결과

당연히, StepFun, Megvii Technology, University of Chinese Academy of Sciences, Tsinghua University 개발을 하였기에 한국어 데이터는 많이 학습 안된것으로 보인다. 하지만 이정도 결과도 상당한 것으로보이는데, Model Tuning을 하면 성능이 엄청 좋아질 것으로 보인다.
주요 기능은 다음과 같다.
- 다양한 입력 형식 지원 (사진, 문서 등)
- 포맷팅된 출력 생성 (마크다운, LaTeX 등)
- 영역 기반 인식, 동적 해상도 조정, 다중 페이지 OCR 등 고급 기능
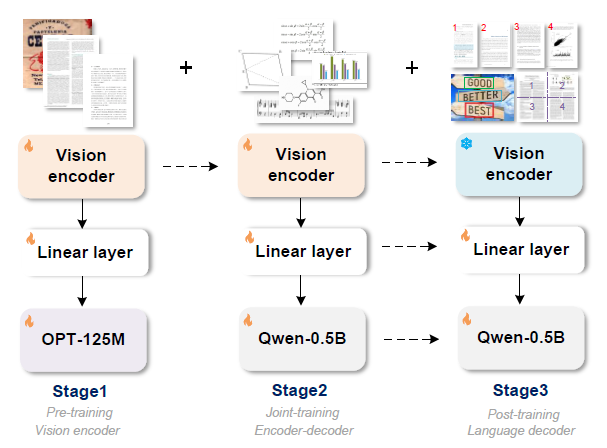
또한, 위 그림을 살펴보면 Vision Transformer(ViT) 기반으로 인코더를 구축하고 디코더는 Qwen-0.5B 구축되어 8K 토큰의 긴 컨텍스트를 처리할 수 있다고 나온다. 일반 텍스트부터 복잡한 구조화된 데이터를 처리할 수 있는게 핵심이 아닐까 싶다.
GOT-OCR2.0은 OCR 기술의 새로운 방향을 오픈소스로 공개하고있습니다. 텍스트 인식의 정확도와 다양성을 크게 높임으로써, 정보 접근성과 분석의 새로운 가능성을 제시하고 있습니다.
해당 논문은 다음에서 읽어보는걸 추천한다.
https://arxiv.org/abs/2409.01704
General OCR Theory: Towards OCR-2.0 via a Unified End-to-end Model
Traditional OCR systems (OCR-1.0) are increasingly unable to meet people's usage due to the growing demand for intelligent processing of man-made optical characters. In this paper, we collectively refer to all artificial optical signals (e.g., plain texts,
arxiv.org
https://github.com/Ucas-HaoranWei/GOT-OCR2.0
GitHub - Ucas-HaoranWei/GOT-OCR2.0: Official code implementation of General OCR Theory: Towards OCR-2.0 via a Unified End-to-en
Official code implementation of General OCR Theory: Towards OCR-2.0 via a Unified End-to-end Model - Ucas-HaoranWei/GOT-OCR2.0
github.com
'02. Study > Pytorch' 카테고리의 다른 글
| [Monkey Patch] Pytorch 몽키패치 사용하기 (0) | 2024.12.02 |
|---|---|
| FLUX.1 Controlnet 사용하기 (4) | 2024.08.19 |
| 2. Pytorch - Autograd (0) | 2020.02.24 |
| 1. Pytorch - Tensor (0) | 2020.02.24 |
