
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- 딥러닝
- tensorflow update
- #English
- #영어 명언
- #opencv
- 영어명언
- 영어
- findContours
- python 알고리즘
- #Android
- text2img
- #실생활영어
- python list
- #1일1영어
- #프로젝트
- #일상영어
- word embedding
- Convolution Neural Network
- #실생활 영어
- 이미지 생성
- tokenizing
- convexhull
- keras
- #영어
- object detection
- c언어
- python __init__
- TensorFlow
- 완전탐색
- opencv SURF
- Today
- Total
When will you grow up?
Flux보다 100배 빠른 Sana 본문
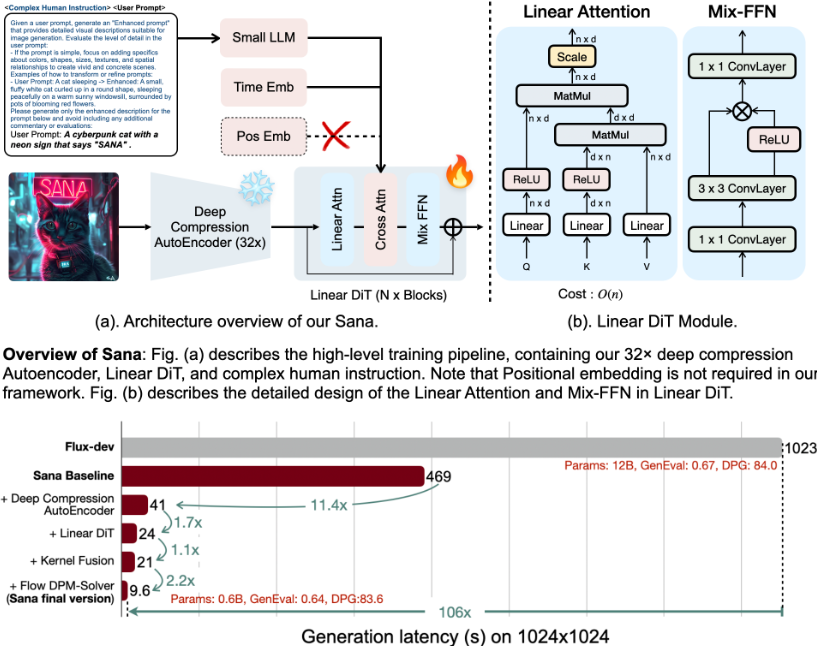
NVIDIA, MIT, Tsinghua University 연구진이 공동 연구한 Sana,
최대 4096 x 4096 해상도의 이미지를 효율적으로 생성할 수 있는 Text to Image 프레임워크??!
특히, 관심을 많이 가지고 있는 Flux 모델에 비해 100배 빠른 속도로 생성이 가능하고 16G GPU에서도 1024x1024 기준으로 1초 미만으로 이미지를 생성할 수 있다는점!
"번역"
Sana-0.6B 모델은 최신 대형 확산 모델(예: Flux-12B)과 비교해 20배 작은 크기로 100배 이상 빠른 처리량을 보여줍니다1
. 16GB 노트북 GPU에서 1024 × 1024 해상도 이미지를 1초 미만으로 생성할 수 있습니다
주요 특징은 다음과 같습니다.
- 깊은 압축 오토인코더: 기존 8배 압축에서 32배로 압축률을 높여 레이턴트 토큰 수를 대폭 줄였습니다
- 선형 DiT: 기존의 어텐션을 선형 어텐션으로 대체해 고해상도에서 효율성을 높였습니다
- 디코더 전용 텍스트 인코더: T5 대신 Gemma라는 소형 LLM을 사용해 텍스트 이해력을 향상시켰습니다
- 효율적인 학습 및 샘플링: Flow-DPM-Solver를 도입해 샘플링 단계를 줄이고 수렴 속도를 높였습니다
해당 링크에서 추론 속도 영상도 보여지며 아직 소스 공개는 안되었지만 곧 나올것으로 보입니다.
https://nvlabs.github.io/Sana/
Sana
About Sana We introduce Sana, a text-to-image framework that can efficiently generate images up to 4096 × 4096 resolution. Sana can synthesize high-resolution, high-quality images with strong text-image alignment at a remarkably fast speed, deployable on
nvlabs.github.io
Paper
https://arxiv.org/abs/2410.10629
SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformers
We introduce Sana, a text-to-image framework that can efficiently generate images up to 4096$\times$4096 resolution. Sana can synthesize high-resolution, high-quality images with strong text-image alignment at a remarkably fast speed, deployable on laptop
arxiv.org